
Welcome to the first in a series of posts aimed at users of the R programming language who wish to become more familiar with Highcharts and the R package highcharter. If you love doing data science with R and creating interactive data visualizations, these posts are for you.
The content for the first couple of posts is adapted from my book Reproducible Finance with R but these posts will delve deeper into highcharter while the book also covers a broader range of topics like data wrangling, transforming, modeling and building Shiny applications.
Today, we will visualize asset returns with line charts, column charts and scatter plots. Next time we will move to some more complex work by adding regression lines and simulation results. Future posts will visualize macroeconomic data like the BLS jobs reports and GDP numbers.
Let’s get to it!
For our data, we will work with 5 years of monthly returns for the 5 ETFs below.
+ SPY (S&P500 fund)
+ EFA (a non-US equities fund)
+ IJS (a small-cap value fund)
+ EEM (an emerging-mkts fund)
+ AGG (a bond fund)And we will need the following packages.
library(tidyverse)
library(timetk)
library(kableExtra)
library(highcharter)Since this isn’t a post about wrangling and transforming data with R, I won’t go through the logic of how to import the price data and transform to monthly returns (for the curious see this post), but the full code to do so is here.
symbols <-
c("SPY","EFA", "IJS", "EEM","AGG")
prices <-
getSymbols(symbols,
src = 'yahoo',
from = "2013-01-01",
to = "2017-12-31",
auto.assign = TRUE,
warnings = FALSE) %>%
map(~Ad(get(.))) %>%
reduce(merge) %>%
`colnames<-`(symbols)
prices_monthly <-
to.monthly(prices,
indexAt = "last",
OHLC = FALSE)
asset_returns_xts <-
na.omit(Return.calculate(prices_monthly,
method = "log"))
asset_returns_xts <- asset_returns_xts * 100
asset_returns_long <-
prices %>%
to.monthly(indexAt = "last",
OHLC = FALSE) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
gather(asset, returns, -date) %>%
group_by(asset) %>%
mutate(returns =
(log(returns) - log(lag(returns))) *100
) %>%
na.omit()We will be working with the two data objects that hold our monthly asset returns. The first is called asset_returns_xts. Have a look at the first few rows.
SPY EFA IJS EEM AGG
2013-02-28 1.267821 -1.296938 1.6175381 -2.310525 0.58911556
2013-03-28 3.726766 1.296938 4.0257940 -1.023505 0.09849772
2013-04-30 1.903006 4.896773 0.1222544 1.208504 0.96389678
2013-05-31 2.333571 -3.065563 4.1976371 -4.948359 -2.02136579
2013-06-28 -1.343432 -2.715331 -0.1402974 -5.473912 -1.57786534
2013-07-31 5.038578 5.186029 6.3541287 1.315986 0.26879677There is one column for each of our ETF monthly returns, but notice the date is in a nameless column. In fact, the date is not in a column at all, it’s considered the time based index of this matrix.
Compare that to asset_returns_long.
| date | asset | returns |
|---|---|---|
| 2013-02-28 | SPY | 1.267821 |
| 2013-03-28 | SPY | 3.726766 |
| 2013-04-30 | SPY | 1.903007 |
| 2013-05-31 | SPY | 2.333571 |
| 2013-06-28 | SPY | -1.343432 |
| 2013-07-31 | SPY | 5.038578 |
This object has a column called date, a column called asset and a column called returns. It’s considered a long data object because the ETFs are stacked in rows, whereas asset_returns_xts is considered a wide data object because each ETF has its own column and makes the object wider. asset_returns_long and asset_returns_xts hold the exact same information, but in different formats. We will examine how to visualize both with highcharter because both are popular data formats in the financial world.
Let’s start with asset_returns_xts and use the Highstock part of the Highcharts toolchain. To call this functionality from R, we start with highchart(type = "stock") and then supply the data to be charted. Note we specify type = “line” but that’s not necessary because the default is a line chart.
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "line")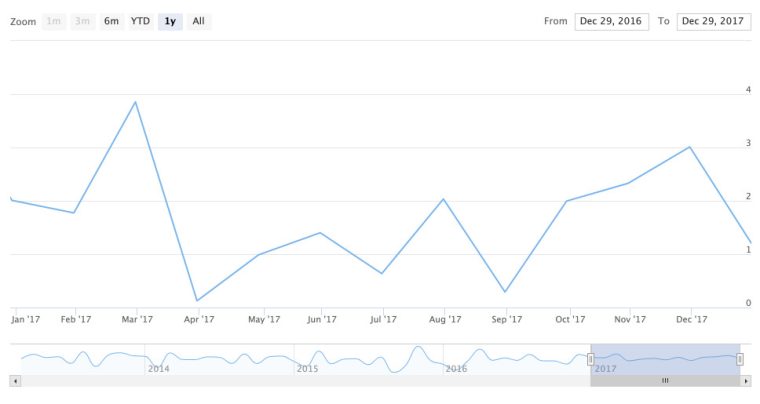
Two short lines of code and a pretty nice interactive time series! Have a look at the chart and notice it has a navigator on the bottom and a date range selector at the top right. We did not have to code those, highchart(type = "stock") creates them by default as a very nice feature for our end users.
If we prefer a different color, we can change it with color = "green".
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY,
type = "line",
color = "green")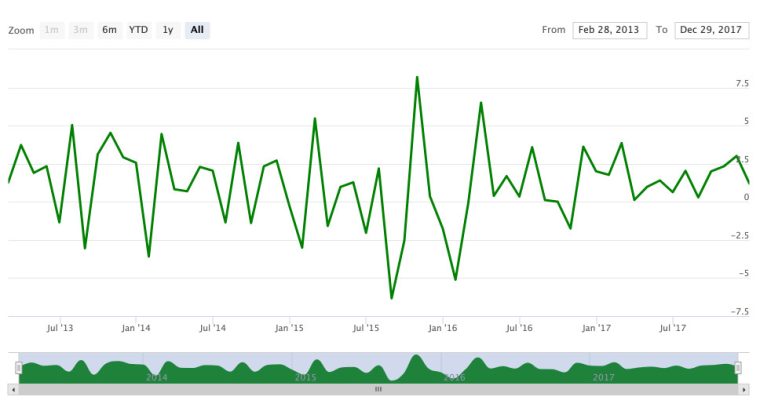
What if we want a column chart instead of a line chart? It’s the same code flow, except we specify type = "column".
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "column")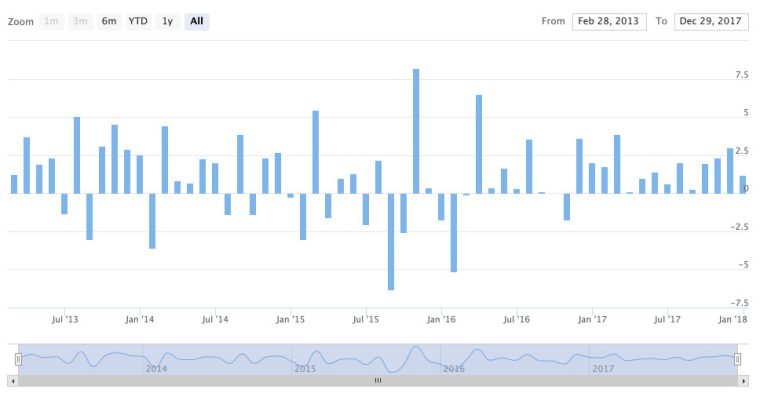
Hover on both of those charts and notice how the tooltip automatically pulls up the date from the x-axis.
For a scatter plot, we use the same code flow, changing to type = "scatter", but let’s also add in the returns for the EFA ETF by appending hc_add_series(asset_returns_xts$EFA). We could do this for all 5 of our ETF, adding them line by line, to put all 5 on the same scatter plot.
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "scatter") %>%
hc_add_series(asset_returns_xts$EFA, type = "scatter")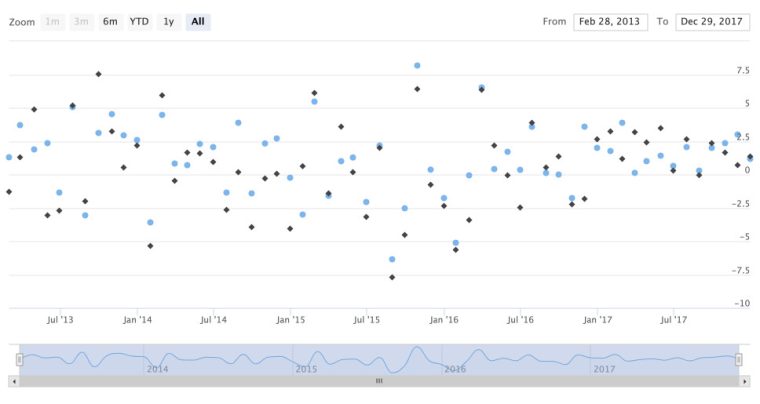
NAThat chart looks how we want, but mouse over a point and notice a few suboptimal aesthetic features. First, the tooltip is not displaying the date the same that it appears on the x-ais. Second, it is displaying the full y-axis values out to more than 10 decimal places and, third, it is referring to the two ETFs as series 1 and series 2, because we have not supplied a name. Let’s fix these three issues.
First, the names of the series are easy to add with name = "SPY" and name = "EFA".
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "scatter", name = "SPY") %>%
hc_add_series(asset_returns_xts$EFA, type = "scatter", name = "EFA")Next, we modify the tooltip format by adding hc_tooltip(pointFormat = ) to the flow and changing the format of the x-point display with {point.x:%Y-%m-%d}. This is telling the tooltip to use a date format.
We then change the y-point display with {point.y:.4f}%, which is telling the tooltip to round to four decimal places and then put a % sign after it. Try changing this to {point.y:.8f} and see the results.
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "scatter", name = "SPY") %>%
hc_add_series(asset_returns_xts$EFA, type = "scatter", name = "EFA") %>%
hc_tooltip(pointFormat = '{point.x: %Y-%m-%d}
{point.y:.4f}%')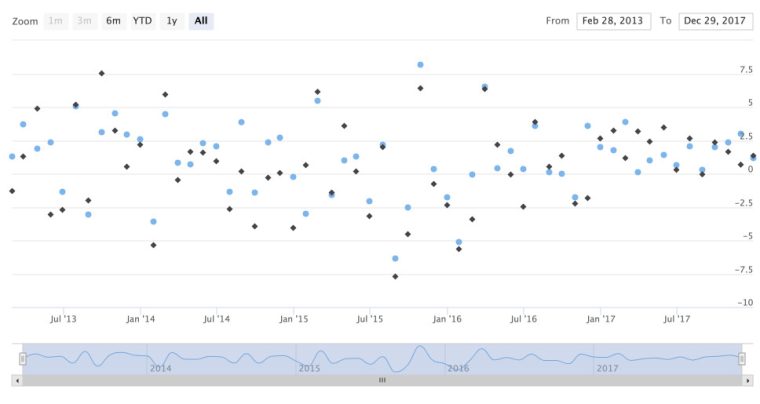
I like the default colors chosen by highcharter but we can customize them with the color argument.
highchart(type = "stock") %>%
hc_add_series(asset_returns_xts$SPY, type = "scatter", name = "SPY", color = "lightblue") %>%
hc_add_series(asset_returns_xts$EFA, type = "scatter", name = "EFA", color = "pink") %>%
hc_tooltip(pointFormat = '{point.x: %Y-%m-%d}
{point.y:.4f}% ')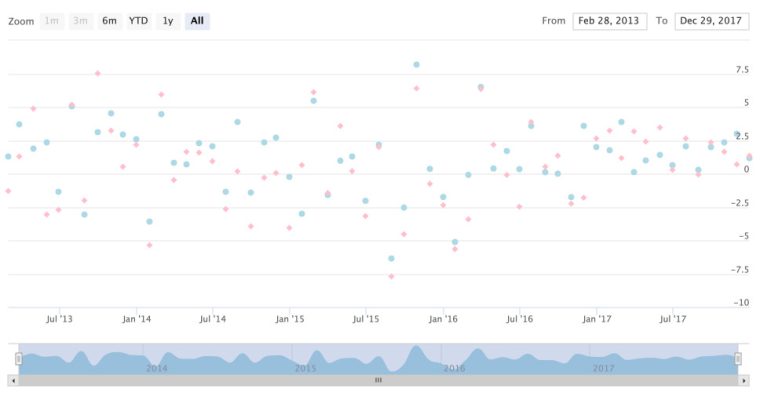
That’s all for data held in asset_returns_xts, let’s explore how to build these same visualizations from long formatted data.
Recall the structure of asset_returns_long.
| date | asset | returns |
|---|---|---|
| 2013-02-28 | SPY | 1.267821 |
| 2013-03-28 | SPY | 3.726766 |
| 2013-04-30 | SPY | 1.903007 |
| 2013-05-31 | SPY | 2.333571 |
| 2013-06-28 | SPY | -1.343432 |
| 2013-07-31 | SPY | 5.038578 |
If we wish to create a line chart of the returns for SPY, we cannot select the SPY column because there is no column called SPY. We need to filter for when the asset column equals SPY by calling filter(asset == "SPY").
asset_returns_long %>%
filter(asset == "SPY") %>%
head()| date <date> | asset <chr> | returns <dbl> |
|---|---|---|
| 2013-02-28 | SPY | 1.267821 |
| 2013-03-28 | SPY | 3.726766 |
| 2013-04-30 | SPY | 1.903007 |
| 2013-05-31 | SPY | 2.333571 |
| 2013-06-28 | SPY | -1.343432 |
| 2013-07-31 | SPY | 5.038578 |
Now we pass that data to hchart() using the %>% operator, which passes data from function to function.
When we run asset_returns_long %>% filter(asset == "SPY"), we are filtering to the SPY observations and then passing them to hchart() with hchart(.). That . inside the parentheses is telling hchart to use the filtered data. This might seem a bit verbose but with this flow, we can quickly filter on different conditions and then pass the result to hchart(), which can come in quite handy if we wish to filter on something like date instead of asset (as we will later).
We are not done yet, though, because we need to specify the type of chart again with type = “line” and then map our aesthetics with hcaes(x = date, y = returns). Why do we need to call hcaes here but we did not need to do so previously? It all goes back to the data structure. asset_returns_xts has no date column, the dates are in the index and highcharter defaults to using that index. asset_returns_long has a date column, but highcharter has no way of knowing we want that date column on the x-axis unless we explicitly tell it so.
asset_returns_long %>%
filter(asset == "SPY") %>%
hchart(.,
type = "line",
hcaes(x = date,
y = returns))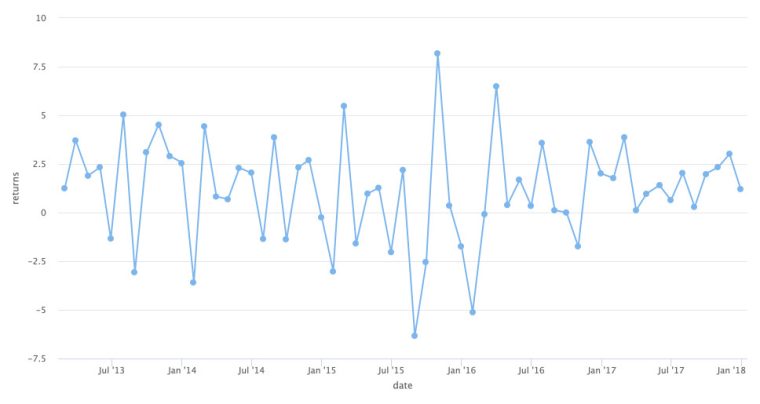
Notice a few differences between this chart and the previous line chart. First, there is no navigator or date selector here. We lost that when we took away highchart(type = "stock"). Also, the y-axis defaulted to being on the left-hand side. I like that better – maybe you hate it! It can be changed back to the right side with hc_yAxis(opposite = TRUE). For good measure, let’s add a % label to the y-axis as well, by calling labels = list(format = “{value}%”)
asset_returns_long %>%
filter(asset == "SPY") %>%
hchart(.,
type = "line",
hcaes(x = date,
y = returns)) %>%
hc_yAxis(opposite = TRUE,
labels = list(format = "{value}%"))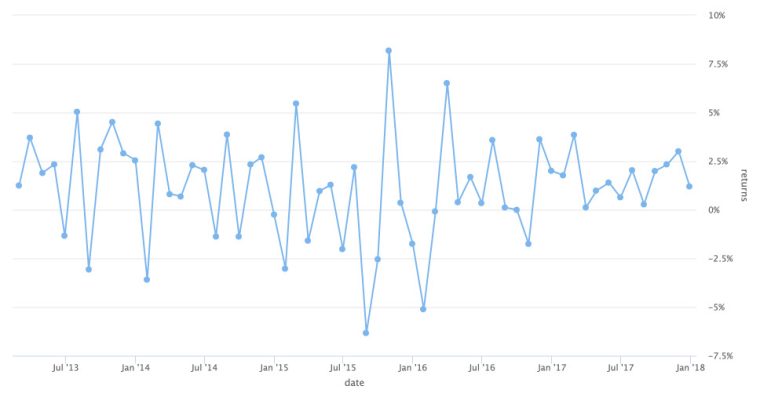
We can use the exact same code flow to create a column chart, by changing to type = "column". I also want the name of the data to appear in the tooltip, which can be done with name = "SPY".
asset_returns_long %>%
filter(asset == "SPY") %>%
hchart(.,
type = "column",
hcaes(x = date,
y = returns),
name = "SPY") %>%
hc_yAxis(opposite = TRUE,
labels = list(format = "{value}%"))Finally, let’s create a scatter plot from our tidy, long formatted data. We change to type = "scatter" and again need to specify our tooltip format with hc_tooltip(pointFormat = '{point.x:%Y-%m-%d}...).
asset_returns_long %>%
filter(asset == "SPY") %>%
hchart(.,
type = "scatter",
hcaes(x = date,
y = returns),
name = "SPY") %>%
hc_yAxis(opposite = TRUE,
labels = list(format = "{value}%")) %>%
hc_tooltip(pointFormat = '{point.x:%Y-%m-%d}
{point.y: .4f}%')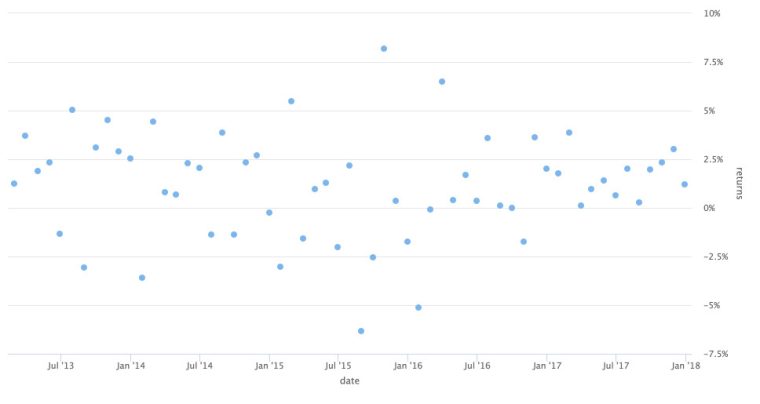
Alright, that was quite a bit of work to build the same charts twice. Let’s do something different and examine how our tidy, long data can be used to efficiently create more interesting charts.
Suppose we wish to scatter all of our ETF data on one charty and color by group. We could go back to original flow and use hc_add_series for each ETF but that would get a bit tedious. With our tidy data flow, we can delete the filter(asset == "SPY") and then add hcaes(...group = asset). This tells highcharter to color each ETF differently, according to its group. Notice how it also creates a legend and includes the ETF name in the tooltip.
asset_returns_long %>%
hchart(.,
type = "scatter",
hcaes(x = date,
y = returns,
group = asset)) %>%
hc_yAxis(opposite = TRUE,
labels = list(format = "{value}%")) %>%
hc_tooltip(pointFormat = '{point.x:%Y-%m-%d}
{point.y: .4f}%')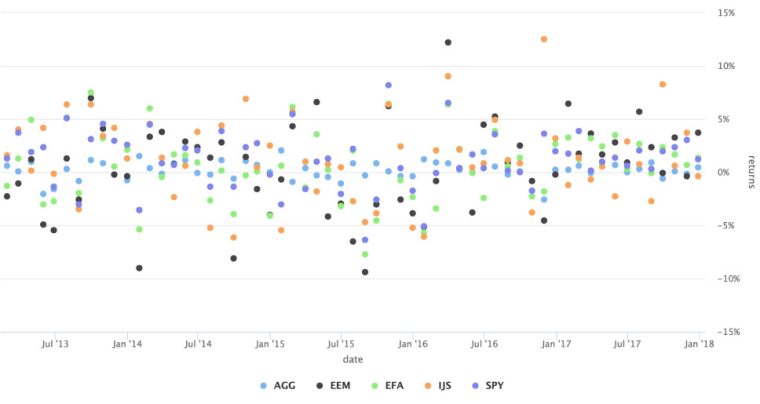
We can quickly see that the lowest monthly return was EEM in August of 2015.
It might be nice to create a column chart, but only for the monthly returns in 2017. Here is where the flexibility of filtering helps. We can call filter(date >= "2017-01-01" & date <= "2018-01-01") to isolate the months in 2017, and then build our column chart.
asset_returns_long %>%
filter(date >= "2017-01-01" & date < "2018-01-01") %>%
hchart(., type = "column",
hcaes(x = date,
y = returns,
group = asset)) %>%
hc_yAxis(opposite = FALSE,
labels = list(format = "{value}%")) %>%
hc_tooltip(pointFormat = '{point.x: %Y-%m-%d}
{point.y:.4f}% ')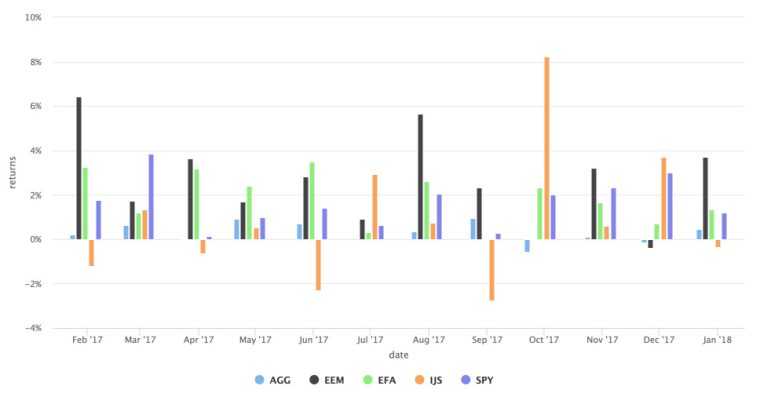
Notice how the returns are naturally grouped together by date in the column format, which helps with comparing each ETF by month. IJS looks to have been the most volatile in 2017 and this looks like a good candidate for a Shiny application where an end user can choose a custom date period and set of ETFs to chart.
That’s all for today. Next time we will explore visualizing the Capital Asset Pricing Model (which is a linear regeression) and the results of a Monte Carlo simulation. See you then and thanks for reading!




Leave a Reply